Voici maintenant des années que le marché de la social data est en plein essor. De plus en plus, on évolue vers des plateformes de veille où l’on nous promet qu’en deux clics, un reporting parfait émergera. Tellement parfait qu’il suffirait de l’envoyer tel quel aux clients. Cette logique de la veille où l’on reçoit tout pour argent comptant est une chimère qui se transforme petit à petit en un véritable danger dans la mesure où la responsabilité de ces reportings incombe de plus en plus à des responsables de projet qui sont de véritables chèvres de la veille.
Incapable de paramétrer les requests qui fondent leur veille, incapable de filtrer leur requête, incapable de voir plus loin que les dashboard, ces François Pignon n’ont qu’une seule capacité : copier-coller des graphiques, sheets et recommandations prêtes à l’emploi dans un PowerPoint. C’est la raison pour laquelle j’estimais plus qu’indispensable, ne serait-ce que par honnêteté intellectuelle de revenir sur tous les chantiers de la veille sur les réseaux sociaux.
I. Le contexte
Signalons d’emblée que les propos ici sont généraux et varient donc en fonction des plateformes, des agences ou des annonceurs.
Tous dépendants des API.
Il existe un grand nombre d’impossibilités techniques dans le champ de la veille. Il faut savoir que les logiciels de veille reposent sur les tunnels que mettent à leur disposition les acteurs du Web. C’est ce qu’on appelle l’API pour Application Programming Interface. Si du jour au lendemain, un acteur du Web change un aspect dans cet API, n’importe quel logiciel de veille en sera affecté. Ces tunnels structurent donc tout ce qu’il est possible ou pas de faire. Si ce que l’on cherche n’est pas fourni par l’API, il est dès lors impossible d’effectuer quoi que ce soit. Ainsi, pour Facebook, il n’est pas possible de faire des recherches sémantiques à travers les profils d’utilisateurs, et ce même si leur post est public. Sur Linkedin, il est impossible d’accéder à presque toutes les informations, sauf les siennes.
De façon globale, il y a également ce qu’on appelle le Dark Web, soit tous les sites qui ne sont pas indexés par les moteurs de recherche. Pour qu’un site soit référencé par ce dernier, il faut que le Webmaster n’ait pas interdit l’interdit aux crawleurs (No-follow) et ou qu’un site référencé pointe vers ce lien non référencé. Tout ce champ n’est pas référencé et n’est donc pas visible par les moteurs de recherche et outils de veille traditionnels.
Tous axé sur la sémantique
Tous les logiciels ou presque ne permettent que de faire des relevés par objet sémantique. (Circonscrire à des mots et à des langues) On pourrait également citer la géolocalisation, mais le nombre d’outils disponible (Uniquement Twitter) et le nombre de personnes ayant activé l’option ne rendent pas la démarche très productive.
À côté de tout le texte et de la linguistique, des initiatives commencent à émerger çà et là autour de la reconnaissance d’image avec plus ou moins de succès. On connaît la recherche de Google par image, mais celle-ci n’est pas encore réellement au point pour ceux qui l’auront expérimenté. De plus, aucun logiciel de veille ne permet d’automatiser un flux par rapport à cela.
Le moteur de recherche de la défense américaine : Memex serait plus adroit que Google pour décrypter les images. Du côté de la veille, une initiative pourrait faire parler d’elle : celle de Talkwalker qui proposerait la reconnaissance d’image pour extraire du contenu en rapport avec les marques. (Sur base des logos, etc.) Dans un monde où l’image et la vidéo prennent de plus en plus d’importance, ce mode de veille devra prendre de l’importance et il y a fort à parier que cela représente un levier de croissance pour les plateformes de veille.
Autre point de contexte, presque toutes les marques utilisent les logiciels de veille pour écouter leur propre nombril : le nom de la marque, les noms de produit, les noms des dirigeants. Quelques marques mettent en place des War Rooms qui scrutent l’entièreté du Web.
Mais presque aucune ne met en place une veille basée sur des personnes. Pourtant, les possibilités et les enseignements peuvent être très importants et les moyens techniques sont tout à fait possibles.
Des conversations qui n’en sont pas
Pas mal de logiciels de veille vantent le fait qu’ils captent des conversations. Sur Twitter ou sur Facebook, les conversations ne sont pas captées. Ce dernier ne propose rien et L’API sur les tweets propose des méta données qui sont : le lien, le hashtag, l’heure du tweet, les personnes mentionnées, les retweets, l’id du tweet… et une catégorie « Reply to id » qui ne fonctionne pas. Cette catégorie permettrait de capter toutes les réponses à un tweet identifié. Comme je pense avoir perdu pas mal de lecteurs dans cette explication, je vais prendre un simple exemple.
Soit un community manager ayant un logiciel de veille qui récupère des tweets autour de sa marque. Il a inscrit « Direct Energie » sur celui-ci et capte tous les tweets comportant la marque. Sur cet exemple :
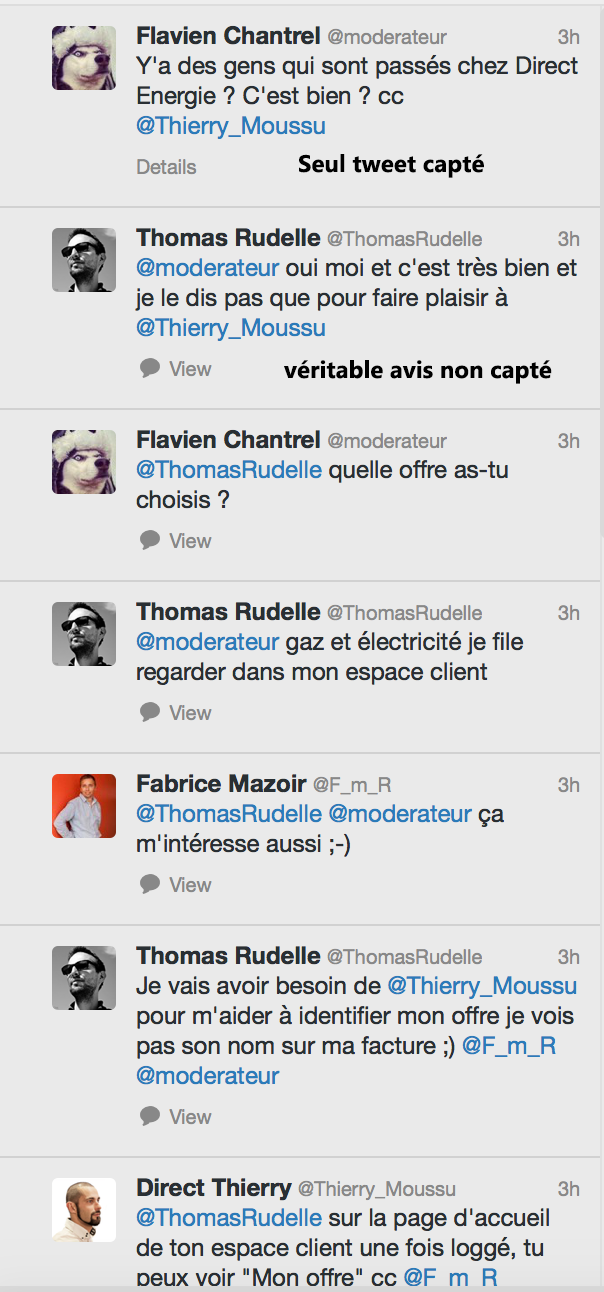
On ne capterait que le premier tweet. Or, ceux qui intéressent les marques sont souvent les tweets N+1, soit les réponses à celui-ci. Et cela, Twitter ne le permet pas malgré une option dans son API. A une question qui serait « Que pensez-vous de la marque X », aucune réponse ou presque ne reprendrait la mention X, ce qui fait que le logiciel de veille ne le traitera jamais.
II. Les indicateurs bidon
1. Le nombre d’impressions.
Vaste fumisterie pourtant présente dans tous les logiciels de veille, le nombre d’impressions est une énorme approximation qui souffre de deux problèmes.
Premièrement, qu’est-ce qu’une impression ? Vous êtes sur votre smartphone, vous naviguez nonchalamment du bout de pouce à travers votre timeline, vous voyez une microseconde un tweet avant que votre pouce ne fasse apparaître d’autres flopées de tweets. 1 impression. Vous êtes maintenant dans votre lit, avec votre iPad, et vous refaites le fil de la journée. 2 impressions. Etc. Une impression n’est qu’une apparition sur un device, et ce même si celle-ci ne se traduit pas par une attention particulière. Depuis peu, sur Twitter, le nombre d’impressions comprend également les « embedded tweets » présents sur les sites en ligne.
L’impression sur les logiciels de veille. Le chiffre affiché sur tous les dashboard n’est qu’une mesure idéale. C’est la somme de tous les followers qui ont partagé les tweets correspondants à la requests que vous avez faite. Si le monitoring s’effectue sur votre compte, il est la somme de vos followers + la somme de tous les followers qui ont retweeté votre tweet.
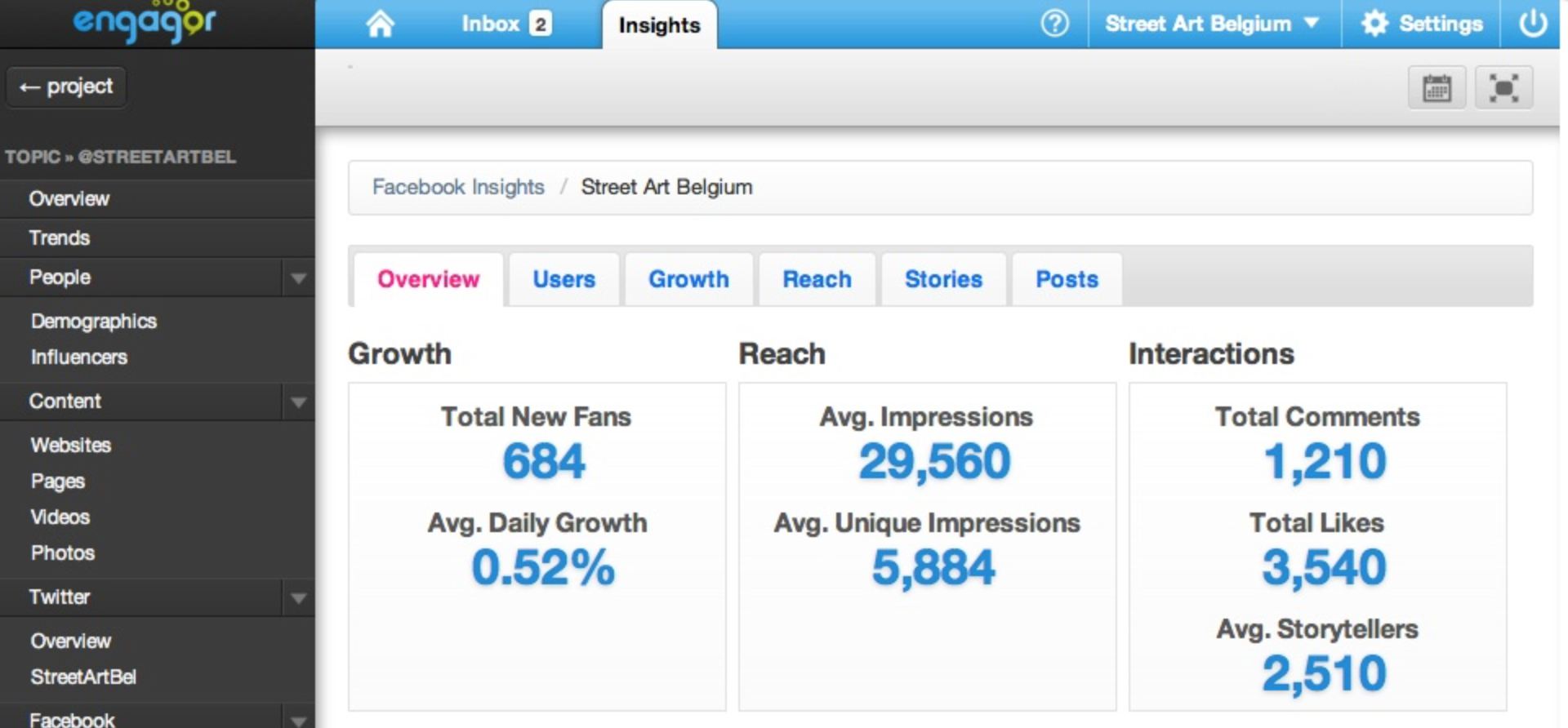
Cela ne comprend donc pas :
- La soustraction des inactifs de votre compte, de ceux qui ne se sont pas connectés, ou qui n’ont jamais vu votre message
- Toutes les impressions gagnées par les embedded tweets sur les médias en ligne, et toutes les impressions glanées par le moteur de recherche ou le suivi d’un hashtag.
Le nombre d’impressions est donc un indicateur fallacieux, et n’est en rien une donnée fiable dans la mesure où des « influenceurs » historiques ont plus de 60 % d’inactifs parmi leurs followers. Il ne peut donc pas être pris pour benchmark ou toute autre chose. Je suis également au regret de vous annoncer que les concours d’influenceur sur certains événements étaient totalement truqués dans la mesure où il suffisait de tweeter avec son gros compte bourré d’inactif pour émerger en vainqueur.
Ces chiffres fallacieux sont dans tous les logiciels de veille, pour la simple raison que l’accès à Twitter Analytics et ses précieux chiffres n’est pas disponible via une quelconque API.
2. Le nombre de vues Facebook.
Autre pure arnaque qui floue pas mal de journalistes lorsqu’ils analysent des buzz. Le nombre de vues affiché par Facebook.

En réalité, ce nombre est totalement gonflé du fait de l’autoplay sur les timelines Facebook. La démonstration a parfaitement été faite par le Blog du Temps. En réalité, il s’agit de l’entièreté des gens qui ont subi une « impression », même s’ils n’ont jamais regardé la vidéo. En allant plus loin dans les statistiques, on voit parfaitement le phénomène :
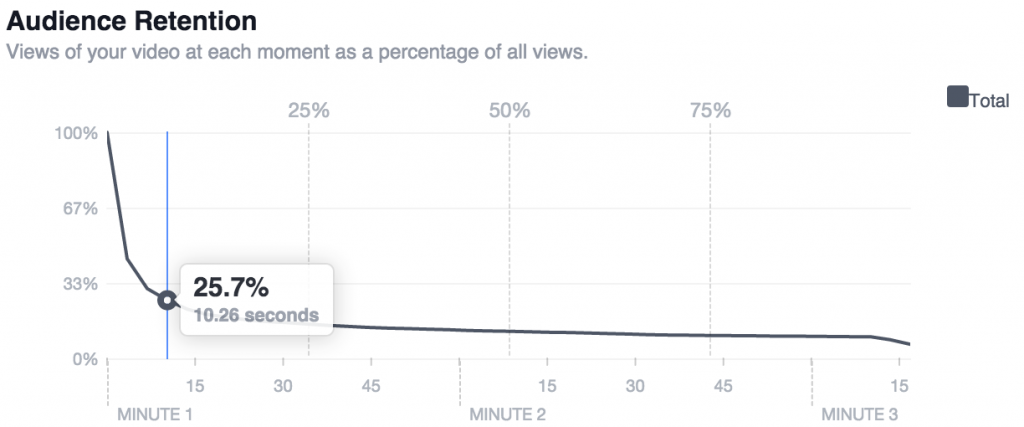
Dans l’exemple montré et qui serait représentatif, l’audience après 10 secondes ne serait plus que de 25,7 %.
3. Le nombre de followers/fans
Je vous renvoie aux égouts de l’influence volume I et volume II pour comprendre pourquoi cela ne veut absolument rien dire.
4. Les magnifiques mappemondes
Absolument magnifiques, elles permettraient de voir l’étendue de son pouvoir à travers le monde. On peut ainsi voir que notre influence s’étend jusqu’au fin fond de la Papouasie Orientale grâce à notre présence Web.
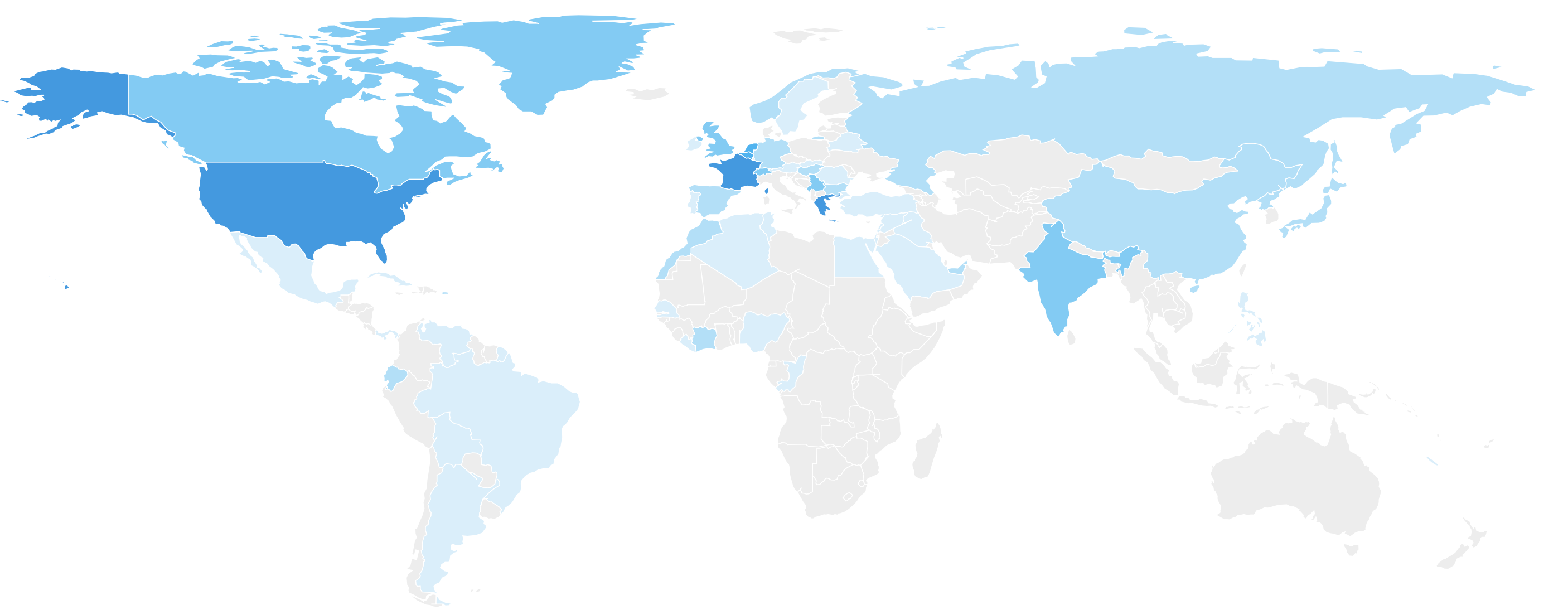
En réalité pas mal de ces chiffres sont totalement tendancieux, voire fallacieux. Tout simplement parce que :
- Pour les articles de Blog et Web, ils tiennent pour la plupart en compte l’emplacement du serveur. Reputatio Lab serait donc italien.
- Pour Twitter, il n’existe en réalité aucune donnée fiable. Pourquoi ? Parce que lorsqu’on s’inscrit, la seule donnée plus au moins « listée » accessible via l’API est le fuseau horaire dans lequel on s’insère. La localité introduite est manuelle et ne peut donc être qu’interprétée via une autre API qui va localiser ce qui est introduit.
- Pour Facebook, il n’y a pas d’accès via API au lieu de la personne.
Ces mappemondes ne sont donc que des effets visuels destinés à impressionner le chaland sur son influence mondiale. Comme cette option est présente dans la plupart des plateformes, les autres copient l’option, la plupart du temps avec la même API.
5. Les algorithmes de tonalité
La plus grosse fumisterie de tous les logiciels de veille : la tonalité des messages en positifs/négatifs et pour les moins charlatan en « neutre ». La plupart du temps, les logiciels de veille se justifieront en disant travailler avec les plus grands laboratoires de linguistique scientifique au monde. Tout ça n’est que de la poudre aux yeux. Je le sais, parce que je n’ai qu’à faire quelques pas pour croiser ces linguistes qui diront tous que ces données ne sont pas fiables, mais qu’on tend vers une « marge d’erreur ». Et puisque l’on parle de marge d’erreur, quelle est-elle ? La plupart des logiciels utilisent des APIs libres à l’emploi. Ces APIS ont été testées dans un Benchmark, comparées à un humain, et menées sur une langue anglaise moins complexe. Voici les résultats :
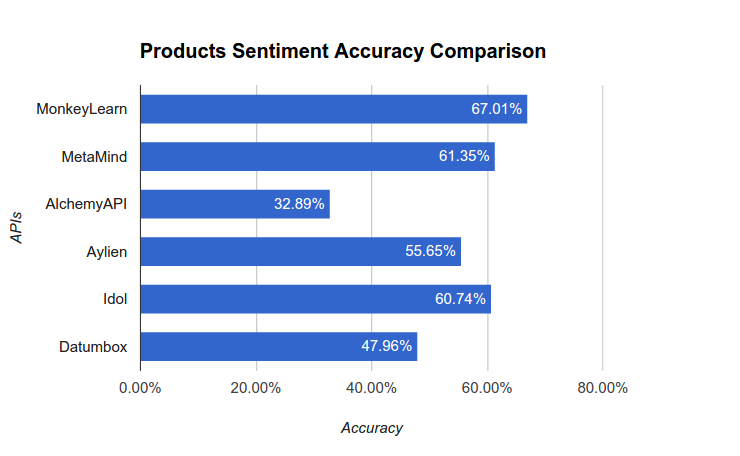
L’API la plus proche ne donnait que 67 % de correspondance avec un humain, soit près de 33 % d’écart !
III. Les mauvaises utilisations
Beaucoup trop de bruits
Parfois, des utilisations peuvent être pas tout à fait parfaites. Je suis toujours étonné par exemple du nombre de volume qui augmente le bruit autour d’une organisation. Des mots génériques qui vont considérablement affecter tous les dashboards. Et des fois, ce bruit vient de là où on ne l’attend pas. EDF, par exemple, subit de plein fouet l’utilisation de l’acronyme pour « équipe de France ». Il est nécessaire de couper ce bruit, et pourtant, peu d’agences de communication le font. La faute à un paramètre opéré par le chargé de clientèle du logiciel de veille qui a tout intérêt à « blinder les requêtes » dans le but d’augmenter le tarif.
Attention aux Worldcloud
Chaque logiciel de veille met à disposition un Wordcloud qui résume les mots les plus utilisés autour des requêtes. Cependant ce Worldcloud a divers soucis :
- Il est fortement influencé par Twitter. Un article de presse n’aura pas le même point que les 2000 tweets.
- Comme il est fortement influencé par Twitter, les titres d’articles auront énormément d’impact sur le WordCloud
- De même, il sera fortement influencé par les tweets les plus retweetés. Une bonne pratique consiste parfois à filtrer les mots sans les retweets. Cependant, tous les logiciels ne proposent pas l’option.
Une méconnaissance des requêtes comprises dans les dashboards
Bien trop souvent, la personne en charge de la gestion de la plateforme de veille ne connaît pas assez les requêtes qui ont été introduites pour générer les dashboards. À ce titre, j’ai une anecdote savoureuse où contacté pour analyser une crise sur les réseaux sociaux, je prends la main de la plateforme fournie à une agence depuis près de 1 mois et demi. Lorsque j’utilise l’API de Twitter, je n’obtiens pas du tout les mêmes résultats que les dashboards donnés par la plateforme de veille. On décide alors de contacter le chargé de clientèle de cette dernière pour lui faire état de grosses incohérences. Il me demande alors de lui montrer un échantillon de tweets non présents sur la plateforme. Une fois la démarche exécutée, il renvoie un mail pour annoncer l’incroyable : lors du paramètre des requêtes, le chargé de clientèle avait oublié d’introduire le nom de la marque dans les requêtes, et ce depuis un mois. Révélateur de la méconnaissance de la partie « back-office » qui prévaut parfois dans la gestion de ces plateformes.
Voilà, j’espère avoir dressé de manière succincte (ce fut dur de limiter la longueur de cet article) les problématiques et enjeux de la veille actuelle. Il est un fait que la veille stratégique sur les réseaux sociaux n’en est qu’à ses débuts et c’est la raison pour laquelle il est à mon sens important de dresser une revue des limites, mais aussi des opportunités de celle-ci.